MySQL的三种排序算法
MySQL内部实现排序主要有3种方式,常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序。
关于排序算法,Youtube上有套有意思的3D机器人演示视频命令,方便理解。
via
快速排序

快速排序视频动画,56秒开始,前面是冒泡法排序
快速排序(英语:Quicksort),又称划分交换排序(partition-exchange sort),简称快排,一种排序算法,最早由东尼·霍尔提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序是对冒泡排序的一种改进。在区间中随机挑选一个元素作基准,将小于基准的元素放在基准之前,大于基准的元素放在基准之后,再分别对小数区与大数区进行排序。
快速排序使用分治法(Divide and conquer, 在计算机科学中,分治法是建基于多项分支递归的一种很重要的算法范式。字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。)策略来把一个序列(list)分为较小和较大的2个子序列,然后递归地排序两个子序列。
步骤为:
挑选基准值:从数列中挑出一个元素,称为“基准”(pivot),
分割:重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(与基准值相等的数可以到任何一边)。在这个分割结束之后,对基准值的排序就已经完成,
递归排序子序列:递归地将小于基准值元素的子序列和大于基准值元素的子序列排序。
递归到最底部的判断条件是数列的大小是零或一,此时该数列显然已经有序。
由于基准是随机的,所以快速排序是不稳定排序。
归并排序
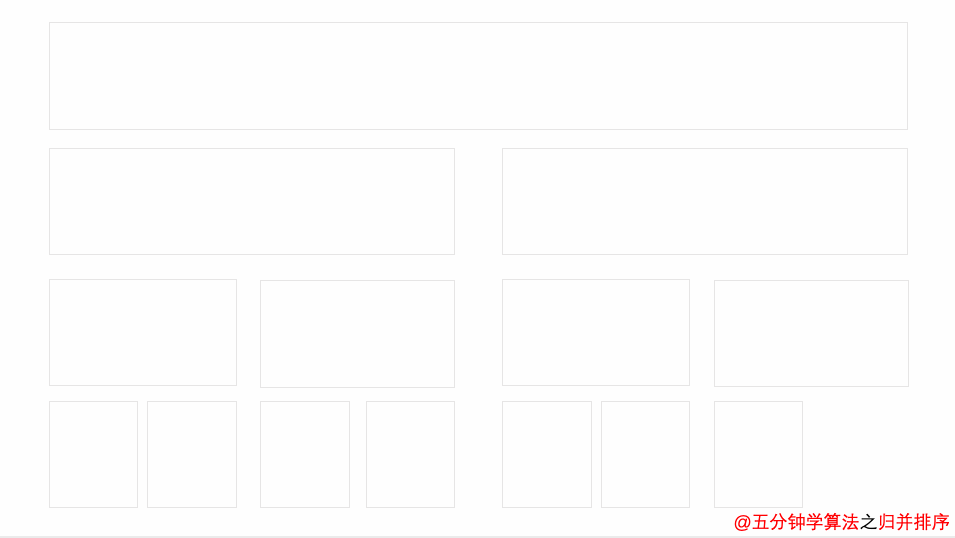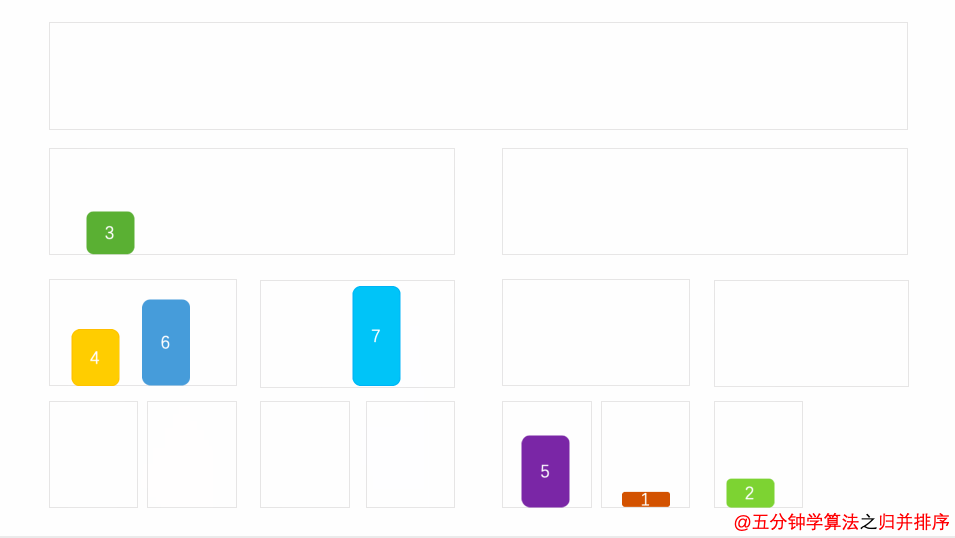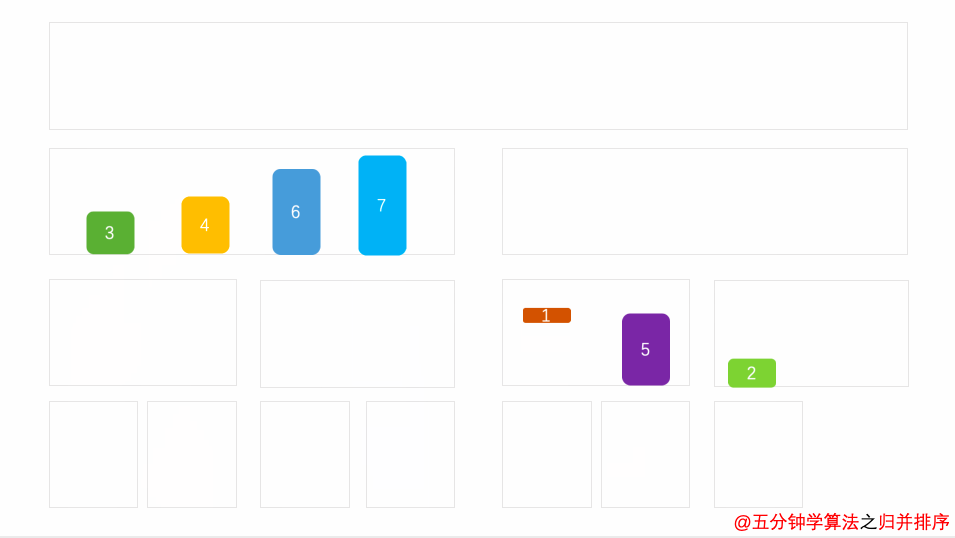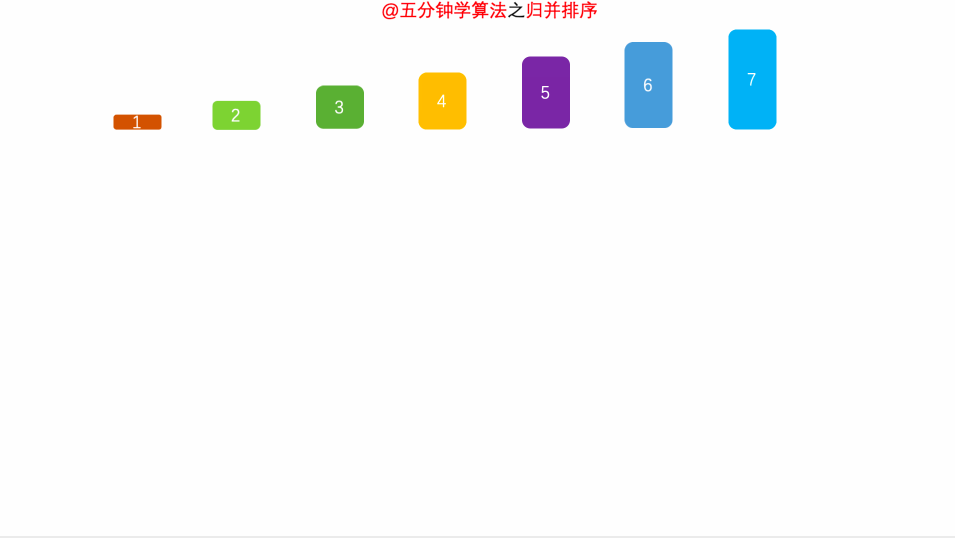
归并排序(英语:Merge sort,或mergesort),是创建在归并操作上的一种有效的排序算法。1945年由约翰·冯·诺伊曼首次提出。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。
把数据分为两段,从两段中逐个选最小的元素移入新数据段的末尾。
可从上到下或从下到上进行。
归并操作
归并操作(merge),也叫归并算法,指的是将两个已经排序的序列合并成一个序列的操作。归并排序算法依赖归并操作。
步骤为:
申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
设定两个指针,最初位置分别为两个已经排序序列的起始位置
比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
重复步骤3直到某一指针到达序列尾
将另一序列剩下的所有元素直接复制到合并序列尾
堆排序

堆排序(英语:Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。
从堆顶把根卸出来放在有序区之前,再恢复堆。
若以升序排序说明,把数组转换成最大堆积(Max-Heap Heap),这是一种满足最大堆积性质(Max-Heap Property)的二叉树:对于除了根之外的每个节点i, A[parent(i)] ≥ A[i]。
重复从最大堆积取出数值最大的结点(把根结点和最后一个结点交换,把交换后的最后一个结点移出堆),并让残余的堆积维持最大堆积性质。
堆的操作
在堆的数据结构中,堆中的最大值总是位于根节点(在优先队列中使用堆的话堆中的最小值位于根节点)。堆中定义以下几种操作:
最大堆调整(Max Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
创建最大堆(Build Max Heap):将堆中的所有数据重新排序
堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
MySQL的排序
a.常规排序
(1).从表t1中获取满足WHERE条件的记录
(2).对于每条记录,将记录的主键+排序键(id,col2)取出放入sort buffer
(3).如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,进行排序并固化到临时文件中。(排序算法采用的是快速排序算法)
(4).若排序中产生了临时文件,需要利用归并排序算法,保证临时文件中记录是有序的
(5).循环执行上述过程,直到所有满足条件的记录全部参与排序
(6).扫描排好序的(id,col2)对,并利用id去捞取SELECT需要返回的列(col1,col2,col3)
(7).将获取的结果集返回给用户。
从上述流程来看,是否使用文件排序主要看sort buffer是否能容下需要排序的(id,col2)对,这个buffer的大小由sort_buffer_size参数控制。此外一次排序需要两次IO,一次是捞(id,col2),第二次是捞(col1,col2,col3),由于返回的结果集是按col2排序,因此id是乱序的,通过乱序的id去捞(col1,col2,col3)时会产生大量的随机IO。对于第二次MySQL本身一个优化,即在捞之前首先将id排序,并放入缓冲区,这个缓存区大小由参数read_rnd_buffer_size控制,然后有序去捞记录,将随机IO转为顺序IO。
b.优化排序
常规排序方式除了排序本身,还需要额外两次IO。优化的排序方式相对于常规排序,减少了第二次IO。主要区别在于,放入sort buffer不是(id,col2),而是(col1,col2,col3)。由于sort buffer中包含了查询需要的所有字段,因此排序完成后可以直接返回,无需二次捞数据。这种方式的代价在于,同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2),如果sort buffer不够大,可能导致需要写临时文件,造成额外的IO。当然MySQL提供了参数max_length_for_sort_data,只有当排序元组小于max_length_for_sort_data时,才能利用优化排序方式,否则只能用常规排序方式。
c.优先队列排序
为了得到最终的排序结果,无论怎样,我们都需要将所有满足条件的记录进行排序才能返回。那么相对于优化排序方式,是否还有优化空间呢?5.6版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式–优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
